

Como criar chatbots com o LangChain

Esta é uma postagem de um convidado, Dido Grigorov, engenheiro de aprendizado profundo e programador Python com 17 anos de experiência na área.

Os chatbots evoluíram muito além de meras ferramentas de perguntas e respostas. Com o poder dos modelos grandes de linguagem (LLMs), os chatbots podem compreender o contexto das conversas e gerar respostas semelhantes às humanas, o que os torna valiosos para aplicações de suporte ao cliente e outros tipos de assistência virtual.
O LangChain, um framework de código aberto, simplifica o processo de criar esses chatbots de conversa, fornecendo ferramentas para a integração transparente de modelos, gerenciamento de contexto e engenharia de prompts.
Nesta postagem de blog, vamos explorar como funciona o LangChain e como os chatbots interagem com os LLMs. Também vamos guiar você passo a passo na criação de um chatbot sensível ao contexto que fornece respostas precisas e relevantes, usando o LangChain e o GPT-3.
O que são chatbots na área de LLMs?
Na área de LLMs, chatbots são um tipo de software de ponta que simula conversas com usuários, semelhantes às conversas destes com humanos, através de interfaces de texto ou voz. Esses chatbots exploram os recursos avançados dos LLMs, que por sua vez são redes neurais treinadas em grandes volumes de dados de texto, o que lhes permite produzir respostas semelhantes às humanas para uma grande variedade de prompts de entrada.
Dentre outras coisas, chatbots baseados em LLMs podem levar o contexto da conversa em consideração ao gerarem uma resposta. Isso significa que eles podem se manter coerentes entre diferentes interações e podem processar consultas complexas para produzirem saídas alinhadas com as intenções do usuário. Além disso, esses chatbots avaliam o tom emocional da entrada do usuário e ajustam suas respostas para se adequarem ao estado de espírito do usuário.
Os chatbots são altamente adaptáveis e personalizados. Eles aprendem com a forma como os usuários interagem com eles. Assim, melhoram suas respostas ajustando-as conforme as preferências e necessidades individuais do usuário.
O que é o LangChain?
O LangChain é um framework de código aberto, desenvolvido para criar aplicativos que usam modelos grandes de linguagem (LLMs). Ele vem com ferramentas e abstrações que permitem personalizar melhor as informações produzidas a partir desses modelos, mantendo a precisão e a relevância.
Uma expressão comum que você pode ver ao ler sobre LLMs é “cadeias de prompts”. Uma cadeia de prompts é uma sequência de prompts ou instruções usadas no contexto de inteligência artificial e aprendizado de máquina, com a finalidade de guiar o modelo de IA através de um processo de várias etapas para gerar resultados mais precisos, detalhados ou refinados. Esse método pode ser empregado em várias tarefas, como redação, solução de problemas ou geração de código.
Os desenvolvedores podem criar novas cadeias de prompts usando o LangChain e este é um dos pontos mais fortes desse framework. É possível até modificar modelos já existentes de prompts sem precisar treinar o modelo novamente ao usar novos conjuntos de dados.
Como funciona o LangChain?
O LangChain é um framework projetado para simplificar o desenvolvimento de aplicativos que usam modelos de linguagem. Ele oferece uma suíte de ferramentas que ajudam os desenvolvedores a criarem e gerenciarem de forma eficiente aplicativos envolvendo processamento de linguagem natural (NLP) e modelos grandes de linguagem. Definindo as etapas necessárias para conseguir o resultado desejado (que pode ser um chatbot, automação de tarefas, um assistente virtual, suporte ao cliente e muito mais), os desenvolvedores podem adaptar modelos de linguagem a contextos específicos de negócios, de forma flexível, usando o LangChain.
Esta é uma visão geral de como o LangChain funciona.
Integração de modelos
O LangChain tem suporte a vários modelos de linguagem, incluindo os da OpenAI, Hugging Face, Cohere, Anyscale, Azure Models, Databricks, Ollama, Llama, GPT4All, Spacy, Pinecone, AWS Bedrock, MistralAI e outros. Os desenvolvedores podem facilmente alternar entre modelos diferentes ou usar diversos modelos em um único aplicativo. É possível criar soluções de integração de modelos desenvolvidos de forma personalizada, o que permite que os desenvolvedores tirem proveito de recursos específicos, sob medida para seus aplicativos.
Cadeias
O conceito central do LangChain é o de cadeias, que reúnem diferentes componentes de IA para obter respostas sensíveis ao contexto. Uma cadeia representa um conjunto de ações automatizadas entre um prompt de usuário e a saída final do modelo. O LangChain oferece dois tipos de cadeias:
- Cadeias sequenciais: permitem que a saída de um modelo ou função seja usada como entrada para outro modelo ou função. Isso é especialmente útil ao elaborar processos com várias etapas que dependem umas das outras.
- Cadeias paralelas: permitem a execução simultânea de diversas tarefas, com suas saídas reunidas ao final. Isso é perfeito para executar tarefas que possam ser divididas em subtarefas completamente independentes.
Memória
O LangChain facilita o armazenamento e a recuperação de informações entre várias interações. Isso é essencial quando for necessário que o contexto persista, como no caso de chatbots ou agentes interativos. O LangChain também oferece dois tipos de memória:
- Memória de curto prazo — ajuda a acompanhar as sessões recentes.
- Memória de longo prazo — permite reter as informações das sessões anteriores, melhorando a capacidade do sistema de recordar chats anteriores e as preferências dos usuários.
Ferramentas e utilitários
O LangChain oferece muitas ferramentas, mas as mais usadas são Prompt Engineering, Data Loaders e Evaluators. No que diz respeito a Prompt Engineering, o LangChain contém utilitários para criar bons prompts, o que é muito importante para obter as melhores respostas dos modelos de linguagem.
Se você quiser carregar arquivos em CSV, PDF ou outro formato, os Data Loaders ajudarão você a carregar e pré-processar diferentes tipos de dados, tornando possível usar esses dados em interações de modelos.
A avaliação é uma parte essencial do trabalho com modelos de aprendizado de máquina e modelos grandes de linguagem. É por isso que o LangChain oferece os Evaluators — ferramentas usadas para testar modelos de linguagem e cadeias para que os resultados gerados satisfaçam aos critérios necessários, que podem incluir:
Critérios para conjuntos de dados:
- Exemplos com curadoria manual: para começar com dados de entrada de alta qualidade e diversificados.
- Registros históricos: para usar dados e feedback reais de usuários.
- Dados sintéticos: para gerar exemplos baseados nos dados iniciais.
Tipos de avaliações:
- Humana: pontuação e feedback manuais.
- Heurística: funções baseadas em regras, com ou sem referências.
- LLM como árbitro: LLMs pontuam as saídas, com base em critérios codificados neles.
- Em pares: comparação de duas saídas, escolhendo a melhor.
Avaliações de aplicativos:
- Testes de unidade: verificações heurísticas rápidas.
- Testes de regressão: medem mudanças no desempenho ao longo do tempo.
- Retestagem: reprocessamento de dados de produção em novas versões.
- On-line: avaliações em tempo real, muitas vezes para fins de salvaguardas e classificações.
Agentes
Os agentes do LangChain são essencialmente entidades autônomas que usam LLMs para interagirem com os usuários, executarem tarefas e tomarem decisões com base em entradas em linguagem natural.
Agentes orientados por ações usam modelos de linguagem para decidirem ações ideais para tarefas predefinidas. Do outro lado, agentes interativos ou aplicações interativas como chatbots usam esses agentes, que também levam em conta a entrada fornecida pelo usuário e a memória armazenada ao responderem a consultas.
Como os chatbots funcionam com LLMs?
Os LLMs por trás dos chatbots usam compreensão de linguagem natural (NLU) e geração de linguagem natural (NLG), que são possibilitadas pelo pré-treinamento de modelos com um volume imenso de dados de texto.
Compreensão de linguagem natural (NLU)
- Sensibilidade ao contexto: LLMs podem compreender as sutilezas e referências de uma conversa e acompanhar conversas de uma sessão para outra. Isso possibilita que os chatbots gerem para os clientes respostas lógicas e apropriadas para o contexto.
- Reconhecimento de intenção: Esses modelos devem ser capazes de compreender a intenção do usuário a partir de suas consultas, não importando se a linguagem é muito específica ou bastante genérica. Os modelos podem discernir o que o usuário deseja obter e determinar a melhor maneira de ajudá-lo a atingir esse objetivo.
- Análise de sentimentos: Os chatbots podem determinar a emoção do usuário através do tom da linguagem usada e se adaptar ao estado emocional do usuário. Isso aumenta o engajamento do usuário.
Geração de linguagem natural (NLG)
- Geração de respostas: Quando se fazem perguntas a LLMs, as respostas que eles fornecem são corretas, tanto em termos de gramática quanto do contexto. Isso ocorre porque as respostas produzidas por esses modelos imitam a comunicação humana, devido ao treinamento desses modelos em volumes imensos de dados de texto em linguagem natural.
- Criatividade e flexibilidade: Além de respostas simples, chatbots baseados em LLMs podem contar histórias, criar poemas ou dar descrições detalhadas de um problema técnico específico. Portanto, podem ser considerados muito flexíveis em termos do material fornecido.
Personalização e adaptabilidade
- Aprendizado a partir de interações: Chatbots tornam as interações personalizadas, porque têm a capacidade de aprender a partir do comportamento e das escolhas do usuário. Pode-se dizer que eles estão sempre aprendendo, o que os torna mais eficazes e precisos ao responderem perguntas.
- Adaptação a diferentes áreas de conhecimento: Os LLMs podem ser ajustados a determinadas áreas ou especialidades, o que permite que os chatbots atuem como especialistas no assunto em relações com clientes, suporte técnico ou na área de saúde.
Os LLMs são capazes de compreender e gerar texto em diversos idiomas, o que os faz adequados a aplicações em diversos contextos linguísticos.
Como criar o seu próprio chatbot com o LangChain em cinco etapas
Este projeto tem o objetivo de criar um chatbot que use o GPT-3 para procurar respostas dentro de documentos. Primeiro, vamos obter conteúdo de artigos on-line, dividi-los em pedaços pequenos, computar suas inclusões e armazená-los no Deep Lake. Depois, vamos usar a consulta de um usuário para recuperar os pedaços mais relevantes do Deep Lake. Esses pedaços serão incorporados em um prompt para gerar a resposta final com o LLM.
É importante observar que usar LLMs traz o risco de gerar “alucinações”, ou informações falsas. Isso pode ser inaceitável em muitas situações de suporte ao cliente, mas o chatbot ainda pode ser valioso para ajudar os operadores a elaborarem respostas que podem ser verificadas antes de fornecidas aos usuários.
Em seguida, vamos explorar como gerenciar conversas com o GPT-3 e dar exemplos para demonstrar a eficácia deste fluxo de trabalho.
Etapa 1: Criação do projeto, pré-requisitos e instalação das bibliotecas necessárias
Primeiro, crie o projeto do chatbot no PyCharm. Abra o PyCharm e clique em “New project”. Em seguida, dê um nome ao seu projeto.

Depois de terminar a configuração do projeto, faça login no Web site da plataforma de API OpenAI (ou crie uma conta no site) e gere a sua “OPENAI_API_KEY“. Para isso, vá até a seção “API Keys” no menu de navegação à esquerda e clique no botão “+Create new secret key”. Não se esqueça de copiar a sua chave.
Depois disso, obtenha o seu “ACTIVELOOP_TOKEN” criando uma conta no Web site da Activeloop. Depois de fazer login, clique no botão “Create API Token” e você será levado à página de criação de tokens. Também copie esse token.
Depois que você tiver o token e a chave, abra as configurações do PyCharm clicando no botão com três pontinhos junto aos botões “Run” e “Debug” e selecione “Edit”. Você deverá ver esta janela abaixo:

Agora, localize o campo “Environment variables” e o ícone à direita dele. Clique nele. Você verá a janela a seguir:
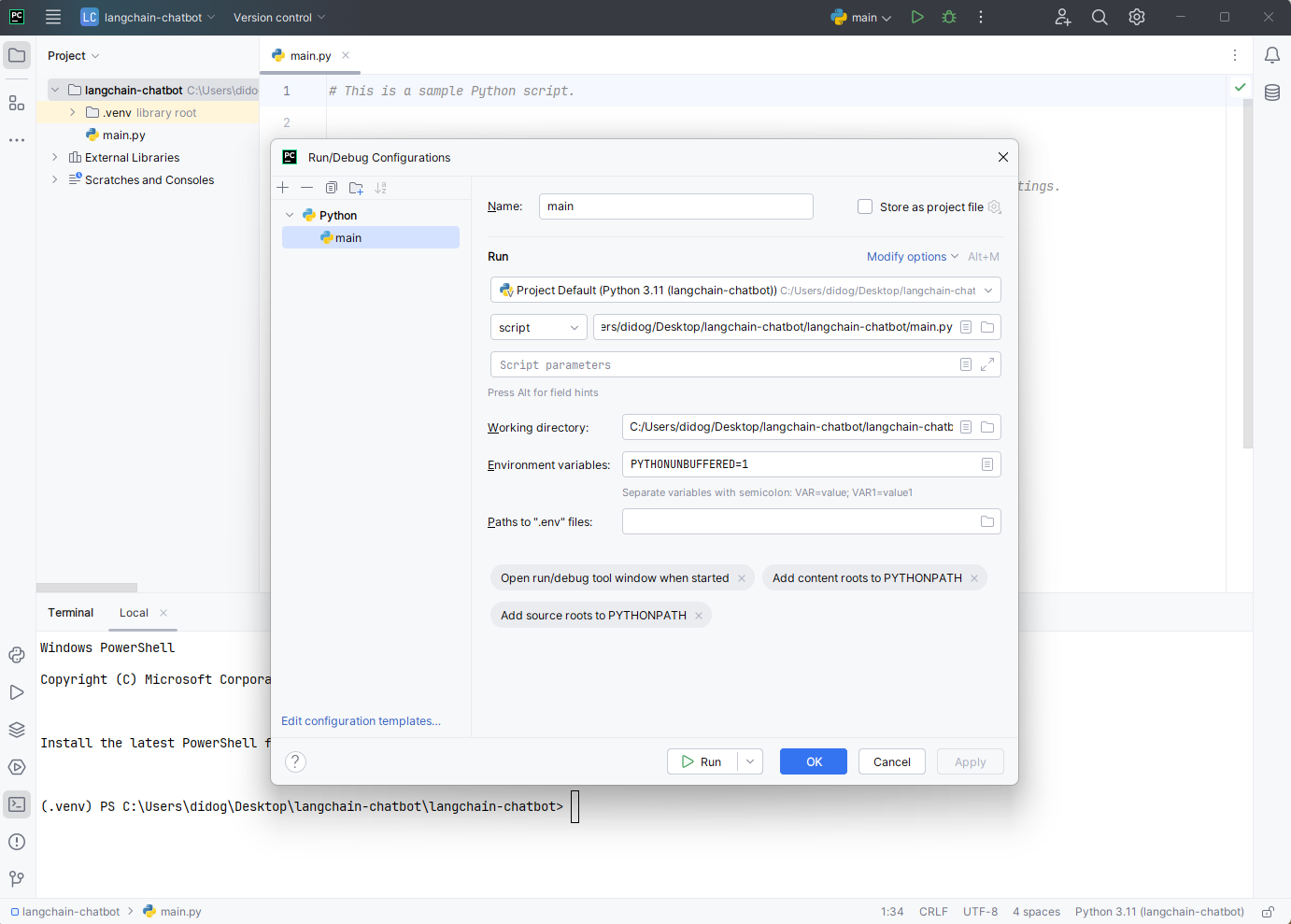
Em seguida, clique no botão “+” para começar a adicionar as suas variáveis de ambiente. Tenha cuidado com os nomes que usar. Os nomes devem ser os mesmos mencionados acima: “OPENAI_API_KEY” e “ACTIVELOOP_TOKEN“. Quando terminar, clique em “OK” na primeira janela e depois em “Apply” e “OK” na segunda.
Essa é uma grande vantagem do PyCharm e eu a adoro, porque o PyCharm cuida das variáveis de ambiente automaticamente para nós, sem precisar fazer chamadas adicionais a elas e nos permitindo pensar mais na parte criativa do código.
Observação: a Activeloop é uma empresa de tecnologia com foco no desenvolvimento de infraestruturas de dados e ferramentas para aprendizado de máquina e inteligência artificial. A empresa tem o objetivo de simplificar o processo de gerenciar, armazenar e processar conjuntos de dados de larga escala, especialmente para aprendizado profundo e outras aplicações de IA.
O Deep Lake é o carro-chefe da Activeloop. Ele oferece recursos eficientes de armazenamento, gerenciamento e acesso a dados e é otimizado para os conjuntos de dados em larga escala que costumam ser usados em IA.
Instalação das bibliotecas necessárias
Usaremos a classe “SeleniumURLLoader” do LangChain, que utiliza as bibliotecas “unstructured” e “selenium” do Python. Instale-as usando o pip. É recomendável instalar a última versão, embora o código tenha sido testado especificamente com a versão 0.7.7.
Para isso, use o seguinte comando no terminal do PyCharm:
pip install unstructured selenium

Agora, precisamos instalar langchain, deeplake e openai. Para isso, basta usar este comando no seu terminal (na mesma janela que você usou para o Selenium) e esperar um pouco até que tudo tenha sido instalado com sucesso:
pip install langchain==0.0.208 deeplake openai==0.27.8 psutil tiktoken
Para garantir que todas as bibliotecas sejam instaladas adequadamente, basta adicionar as linhas a seguir, necessárias para o nosso aplicativo de chatbot, e clicar no botão “Run”:
from langchain.embeddings.openai import OpenAIEmbeddings from langchain.vectorstores import DeepLake from langchain.text_splitter import CharacterTextSplitter from langchain import OpenAI from langchain.document_loaders import SeleniumURLLoader from langchain import PromptTemplate
Outra maneira de instalar as suas bibliotecas é através das configurações do PyCharm. Abra-as e vá até a seção “Project -> Python Interpreter”. Em seguida, localize o botão “+”, pesquise o seu pacote e clique no botão “Install Package”. Depois que terminar, feche a janela e, na janela seguinte, clique em “Apply” e depois em “OK”.

Etapa 2: Dividir o conteúdo em pedaços e computar suas inclusões
Como já mencionado, nosso chatbot irá se “comunicar” usando conteúdo originário de artigos on-line. Foi por isso que escolhi o Digitaltrends.com como minha fonte de dados e selecionei 8 artigos para começar. Todos esses artigos foram organizados em uma lista do Python e atribuídos a uma variável chamada “articles”.
articles = ['https://www.digitaltrends.com/computing/claude-sonnet-vs-gpt-4o-comparison/',
'https://www.digitaltrends.com/computing/apple-intelligence-proves-that-macbooks-need-something-more/',
'https://www.digitaltrends.com/computing/how-to-use-openai-chatgpt-text-generation-chatbot/',
'https://www.digitaltrends.com/computing/character-ai-how-to-use/',
'https://www.digitaltrends.com/computing/how-to-upload-pdf-to-chatgpt/']
Vamos carregar os documentos das URLs fornecidas e os dividir em pedaços, usando “CharacterTextSplitter” com pedaços de tamanho 1000 sem sobreposição:
# Use the selenium to load the documents loader = SeleniumURLLoader(urls=articles) docs_not_splitted = loader.load() # Split the documents into smaller chunks text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0) docs = text_splitter.split_documents(docs_not_splitted)
Se você executar o código que temos até agora e tudo funcionar bem, você deverá receber a seguinte saída:
[Document(page_content="techcrunchnntechcrunchnnWe, TechCrunch, are part of the Yahoo family of brandsThe sites and apps that we own and operate, including Yahoo and AOL, and our digital advertising service, Yahoo Advertising.Yahoo family of brands.nn When you use our sites and apps, we use nnCookiesCookies (including similar technologies such as web storage) allow the operators of websites and apps to store and read information from your device. Learn more in our cookie policy.cookies to:nnprovide our sites and apps to younnauthenticate users, apply security measures, and prevent spam and abuse, andnnmeasure your use of our sites and appsnn If you click '", metadata={'source': ……………]
Em seguida, vamos gerar as inclusões, usando “OpenAIEmbeddings”, e salvá-los em uma armazenagem vetorial do Deep Lake, hospedada na nuvem. Em condições ideais, em um ambiente de produção, poderíamos enviar todo um Web site ou uma aula de um curso para um conjunto de dados do Deep Lake, permitindo fazer consultas em milhares ou até milhões de documentos.
Usando um conjunto de dados sem servidor do Deep Lake na nuvem, aplicativos de vários locais podem acessar um conjunto centralizado de dados de forma transparente, sem precisar configurar uma armazenagem vetorial em uma máquina dedicada.
Por que precisamos de documentos em pedaços e de inclusões?
Ao se criarem chatbots com o LangChain, documentos em pedaços e inclusões são essenciais por vários motivos relacionados à eficiência, precisão e desempenho do chatbot.
As inclusões são representações vetoriais de textos (palavras, frases, parágrafos ou documentos) que capturam sua semântica. Eles encapsulam o contexto e o significado das palavras em um formato numérico. Isso permite que o chatbot compreenda e gere respostas contextualmente apropriadas, capturando nuances, sinônimos e relações entre palavras.
Graças às inclusões, o chatbot também pode identificar e recuperar rapidamente as respostas ou informações mais relevantes a partir de uma base de conhecimento, porque as inclusões permitem associar as consultas do usuário aos pedaços mais semanticamente relevantes de informação, mesmo que a redação da consulta seja diferente.
A divisão em pedaços, por outro lado, envolve dividir documentos grandes em pedaços menores e mais fáceis de administrar. Pedaços menores são mais rápidos para processar e analisar que documentos grandes e monolíticos. Isso resulta em menores tempos de resposta no chatbot.
A divisão dos documentos em pedaços também ajuda na relevância da saída, porque quando um usuário faz uma pergunta, costuma ser a respeito apenas de uma parte específica do documento. A divisão em pedaços permite que o sistema identifique e recupere apenas as seções relevantes e que o chatbot possa fornecer respostas mais precisas e exatas.
Agora, vamos voltar ao nosso aplicativo e atualizar o código a seguir, incluindo o ID da sua organização do Activeloop. Lembre-se que, como padrão, o ID da sua organização é o mesmo que o seu nome de usuário.
# TODO: use your organization id here. (by default, org id is your username)
my_activeloop_org_id = "didogrigorov"
my_activeloop_dataset_name = "jetbrains_article_dataset"
dataset_path = f"hub://{my_activeloop_org_id}/{my_activeloop_dataset_name}"
db = DeepLake(dataset_path=dataset_path, embedding_function=embeddings)
# add documents to our Deep Lake dataset
db.add_documents(docs)
Outro recurso excelente e que eu adoro no PyCharm é a opção de adicionar anotações TODO diretamente em comentários do Python. Basta digitar TODO com tudo em maiúsculas e todas as anotações irão para uma seção do PyCharm onde você poderá visualizá-las todas juntas:
# TODO: use your organization id here. (by default, org id is your username)
Você pode clicar nelas e o PyCharm lhe mostrará diretamente onde elas estão no seu código. Acho esse recurso muito conveniente para os desenvolvedores e o uso o tempo todo:

Se você executar o código que temos até agora e tudo funcionar normalmente, você deverá ver a seguinte saída:

Para encontrar os pedaços mais semelhantes a uma determinada consulta, podemos usar o método “similarity_search”, oferecido pelo armazenamento vetorial do Deep Lake:
# Check the top relevant documents to a specific query query = "how to check disk usage in linux?" docs = db.similarity_search(query) print(docs[0].page_content)
Etapa 3: Criar o prompt para o GPT-3
Vamos criar um modelo de prompt integrando prompts de atuação em papéis, dados pertinentes da base de conhecimento e a consulta do usuário. Esse modelo estabelecerá a persona do chatbot como um agente ostensivo de suporte ao cliente. O modelo aceita duas variáveis de entrada: “chunks_formatted”, contendo os trechos selecionados e pré-formatados dos artigos, e “query”, representando a pergunta do usuário. O objetivo é produzir uma resposta precisa, baseando-se apenas nos pedaços fornecidos, evitando quaisquer informações inventadas ou incorretas.
Etapa 4: Criar a funcionalidade do chatbot
Para gerar uma resposta, começamos obtendo os “k” pedaços (por exemplo, os 3 pedaços) mais semelhantes à consulta do usuário. Então, esses pedaços são formatados como um prompt, que é enviado ao modelo do GPT-3, com um valor de temperatura de 0.
# user question query = "How to check disk usage in linux?" # retrieve relevant chunks docs = db.similarity_search(query) retrieved_chunks = [doc.page_content for doc in docs] # format the prompt chunks_formatted = "nn".join(retrieved_chunks) prompt_formatted = prompt.format(chunks_formatted=chunks_formatted, query=query) # generate answer llm = OpenAI(model="gpt-3.5-turbo-instruct", temperature=0) answer = llm(prompt_formatted) print(answer)
Se tudo funcionar bem, a sua saída deve ser:
To upload a PDF to ChatGPT, first log into the website and click the paperclip icon next to the text input field. Then, select the PDF from your local hard drive, Google Drive, or Microsoft OneDrive. Once attached, type your query or question into the prompt field and click the upload button. Give the system time to analyze the PDF and provide you with a response.
Etapa 5: Criar o histórico de conversas
# Create conversational memory
memory = ConversationBufferMemory(memory_key="chat_history", input_key="input")
# Define a prompt template that includes memory
template = """You are an exceptional customer support chatbot that gently answers questions.
{chat_history}
You know the following context information.
{chunks_formatted}
Answer the following question from a customer. Use only information from the previous context information. Do not invent stuff.
Question: {input}
Answer:"""
prompt = PromptTemplate(
input_variables=["chat_history", "chunks_formatted", "input"],
template=template,
)
# Initialize the OpenAI model
llm = OpenAI(openai_api_key="YOUR API KEY", model="gpt-3.5-turbo-instruct", temperature=0)
# Create the LLMChain with memory
chain = LLMChain(
llm=llm,
prompt=prompt,
memory=memory
)
# User query
query = "What was the 5th point about on the question how to remove spotify account?"
# Retrieve relevant chunks
docs = db.similarity_search(query)
retrieved_chunks = [doc.page_content for doc in docs]
# Format the chunks for the prompt
chunks_formatted = "nn".join(retrieved_chunks)
# Prepare the input for the chain
input_data = {
"input": query,
"chunks_formatted": chunks_formatted,
"chat_history": memory.buffer
}
# Simulate a conversation
response = chain.predict(**input_data)
print(response)
Vamos percorrer o código de forma mais conversacional.
Para começar, vamos criar uma memória das conversas usando “ConversationBufferMemory“. Isso permite que nosso chatbot se lembre do histórico corrente de conversas, usando ‘input_key="input"‘ para gerenciar as entradas que chegarem do usuário.
Em seguida, vamos projetar um modelo de prompt. Esse modelo é como um script para o chatbot, incluindo seções para o histórico do chat, os pedaços de informações que reunimos e a pergunta (entrada) atual do usuário. Essa estrutura ajuda o chatbot a saber exatamente qual contexto ele tem e qual pergunta ele precisa responder.
Depois, vamos prosseguir inicializando a cadeia do nosso modelo de linguagem, ou “LLMChain“. Pense nisso como uma montagem dos componentes: pegamos nosso modelo de prompt, o modelo de linguagem e a memória que criamos antes e combinamos tudo em um único fluxo de trabalho.
Quando chegar o momento de processar uma consulta do usuário, prepararemos a entrada. Isso envolve criar um dicionário que inclua a pergunta do usuário (“input“) e os pedaços relevantes de informações (“chunks_formatted“). Esse arranjo garante que o chatbot tenha todos os dados de que precisa para criar uma resposta bem informada.
Finalmente, geramos uma resposta. Invocamos o método “chain.predict“, passando a ele os dados de entrada que preparamos. O método processa essa entrada através do fluxo de trabalho que criamos e a saída é a resposta do chatbot, que então mostramos.
Essa abordagem permite que nosso chatbot mantenha uma conversa suave e bem informada, lembrando-se das interações anteriores e fornecendo respostas relevantes, baseadas no contexto.
Outro dos meus truques favoritos com o PyCharm, que me ajudou muito a criar esta funcionalidade, foi a possibilidade de posicionar o cursor sobre um método, teclar “CTRL” e clicar no método.

Conclusão
O GPT-3 é excelente para criar chatbots de conversa capazes de responderem perguntas específicas com base em informações de contexto fornecidas no prompt. Porém, pode ser um desafio garantir que o modelo gere respostas baseadas apenas nesse contexto, pois o modelo muitas vezes tende a “alucinar” (isto é, gerar informações novas e potencialmente falsas). O impacto dessas informações falsas depende de cada caso de uso.
Em resumo, desenvolvemos um sistema sensível ao contexto para responder perguntas usando o LangChain, seguindo as estratégias e o código fornecidos. Esse processo incluiu dividir os documentos em pedaços, computar suas inclusões, implementar um buscador para encontrar pedaços semelhantes, criar um prompt para o GPT-3 e usar o modelo do GPT-3 para gerar um texto. Essa abordagem ilustra o potencial de se usar o GPT-3 para criar chatbots poderosos e precisos quanto ao contexto e ao mesmo tempo enfatiza a importância de ser vigilante quanto ao risco de gerar informações falsas.
Sobre o autor


Subscribe to PyCharm Blog updates





